This is a blog about behaviour change science and complex systems in preparedness, health and well-being.
For research articles, see my Google Scholar profile. If you’d like to e-mail me about anything, please email matti.tj.heino @ this domain (i.e. mattiheino.com). Find me in LinkedIn.
This is an English translation of a Finnish post outlining some learnings from our government funded consortium of 5 universities, studying what we can learn from the COVID-19 pandemic response. The interdisciplinary collaboration has significantly influenced how I think of pathogen spread, and I found the post quite enlightening. I hence wanted to share this with a larger audience, because auto-translate tools still don’t work well for Finnish. Original authors are Lotta-Maria Oksanen, Tuomas Aivelo, Viktor Zöldi, and Tarja Sironen.I am grateful to the first author for providing feedback on the translation, but all mistakes in the final text are mine – please report if you see any.
Throughout time, people have pondered how infections spread and how they should be combated. The pandemic changed how we think pathogens in the respiratory tract spread.
Exposure occurring through the air is no longer seen as rare or exceptional. It is now viewed as a daily transmission route for respiratory infections in normal social interaction.
Research on the topic is being conducted in the Government-funded Lessons from the Pandemic Crisis (PAKO) project, which investigates COVID-era actions across different sectors to prepare for future crises. The University of Helsinki [medical faculty]’s sub-study forms a comprehensive picture of the understanding that prevailed in Finland. The study focuses on the view about transmission routes and the changes it faced, and the protection guidelines introduced. It also produces an analysis of the variants observed in Finland during the pandemic, their characteristics, and their speed of arrival.
The Historical View: Droplets at the Center of Infection
Before the pandemic, it was thought that respiratory infections spread via large droplets generated when a symptomatic person coughs or sneezes. These droplets cause infection when hitting the recipient’s mucous membranes, i.e., the eyes, nose, or mouth.
Over a hundred years ago, medicine was living through a time of change. It began to be understood that diseases are caused by pathogens. There was a desire to get rid of old beliefs, such as miasma – polluted air that originated from rotting sources and was believed to cause diseases. Dried saliva mixed with dust was also believed at that time to have great significance in the spread of diseases. Indeed, public spaces read: “Do not spit on the floor.” Studies were conducted in which test subjects, for example, swirled a solution containing bacteria in their mouths and read aloud. Dishes were placed on the floor in front of them, revealing how far the bacteria spread. Bacteria grew especially on the dishes that were close by. In the studies, the significance of fresh secretions was understood, and attention focused on large droplets.
The role of air as a carrier of infections lost apparent credibility even further, when a leading public health scientist Charles Chapin (1856-1941) criticised airborne transmission in his key textbook. He proposed that contact infection is the most central and obvious transmission route. The idea of contact and droplets as dominant modes of transmission lived strong for decades, and thus hand washing and droplets became familiar to everyone in pandemic guidelines as well.
TheNew View: Respiratory Infections Spread Via the Air
The problem with droplet thinking was that smaller particles remain in the air and do not settle on the dish. The old technology simply was not sufficient to observe these. Especially regarding viruses, technical challenges exist even today. Airborne transmission has, however, proven to be central in many transmission events. Advanced measurement methods have shown that nearly all particles we produce are very small and that we produce infectious particles also when breathing. In animal experiments, other transmission routes have been ruled out, demonstrating that infection must have occurred via the air – for example, a seminal research setup that demonstrated the airborne nature of tuberculosis has been replicated also with SARS-CoV-2.
Human experiments have also yielded interesting results. In a study examining Rhinovirus, laboratory-infected “donors” and susceptible volunteers sat playing cards for 12 hours, sitting at a distance of 1.5-2m from each other. Some of the participants had their hands tied so that it was impossible for them to touch their faces, making infection possible only through the air. Infections were equally common among hands-tied and untied groups. In a separate branch of the experiment, where the cards were thoroughly soiled with the infectors’ nasal secretions, but the infectors did not participate in the game, no infections occurred at all.
Correspondingly, many pandemic-era super-spreader events – such as various concert and choir events, many of which observed safety distances – a significant portion of participants still fell ill. Such transmission events are only possible through airborne transmission. While it was previously thought that close proximity was proof of contact infection, it is now understood that exposure to small particles is also highest at close range.
Infection Through the Air: Threat or Opportunity?
Traditionally, air has been considered difficult to control. Modern technologies, such as ventilation, air purification, and respirator-grade masks, however, make it possible to target actions precisely at smaller particles and thus reduce infection risk. The UN held its first Conference on Healthy Indoor Air on 23 September 2025, and safe indoor air was defined as a key objective. Indeed, new international ventilation standards that take infection risks into account, have been proposed for new construction and renovation projects.
Taking airborne infection into account also opens an excellent opportunity to improve patient and occupational safety in social and health care. With awareness, this infection risk can be monitored and combated. Until now, protective guidelines have mainly concerned droplets, leaving a central part of the exposure unnoticed. Noting the airborne nature enables use of personal protective equipment that protects against it. An example would be recognising that the effect of screens or curtains is minimal on respiratory infection in a shared room without other additional measures – such as air purifiers – especially during prolonged exposure.
The Role of Information and the Challenge of Distortion
The pandemic has also made visible another phenomenon: the distortion of information. In the era of social media and rapid communication, research information and carefully collected evidence compete for attention with false information, partisan interpretation, and outright disinformation.
The phenomenon is global, but it escalated, for example, in the United States. Sharp dividing lines regarding e.g. the use of masks and vaccines emerged both spontaneously, and were created purposefully, during the pandemic. Information became a tool for political and ideological maneuvering – instead of a shared foundation for decision making.
Information alone is not enough. Structures and processes are also needed that enable the flow of information and support trust in experts, authorities, and research, as well as dialogue between these actors. Without this trust, even the best possible research information does not translate into action.
The pandemic showed how one can change course in the middle of a crisis if basic trust exists: Finns, for example, quickly adopted masking or kept their distance when the authorities recommended it. Conversely, new ideas do not end up in practice if the opportunity to bring new information to the decision-making table is lacking. Discussion must continue and trust must be built between crises; then the structures will be ready.
Looking Forward
From the history of medicine, we know that it takes a long time before new information changes practices. The necessity of hand washing between handling the deceased and treating living surgeries or deliveries was once difficult to accept. Nowadays, medical breakthroughs are considerably faster, but questioning old ways still often leads to negative reactions first. Over time, through education and dialogue, new information begins to gain a foothold.
Change is an opportunity. With advanced knowledge, we can bring different fields to the same table to solve the problem. For example, we can enhance measures that reduce infection risk in indoor air already in building design, and simultaneously reduce other exposure to particles. In this change, digitalisation and sensor technology offer new possibilities. Smart buildings can adjust ventilation energy-efficiently using real-time data. Collected data, in turn, helps visualise risky spaces and target corrective measures exactly where they are needed most – making healthy indoor air the new norm.
This means that in future epidemics, we will have more means at our disposal than just prohibitions and restrictions. What if in the next pandemic we didn’t have to greet the elderly from behind a window, but could hug them while wearing a respirator-grade mask? Often, it is precisely large structural hygiene changes, such as the cold chain or water purification, that bring significant public health benefits in the long run – is clean indoor air the next great change that also increases everyday health security?
It is time to ask: are we ready to invest in behaviours, technology, and structures that make our workplaces, hospitals, schools, and homes healthier?
Context: This post outlines a manuscript in preparation and exhibits some of its visualisations, partly also presented at the European Public Health Conference (November 2025). If a blog format isn’t your poison, you can also see this video or this one-pager (conference poster).
It’s April 2025. Red Eléctrica, the electricity grid provider for the Iberian Peninsula, declares: “There exists no risk of a blackout. Red Eléctrica guarantees supply.”
Twenty days later, a massive blackout hits Portugal, Spain, and parts of France.
What the hell happened?
To understand this, we need to talk about ladders.
The Ladder Thought Experiment
Let’s take an example outlined in the wonderful article An Introduction to Complex Systems Science and Its Applications: Imagine 100 ladders leaning against a wall. Say each has a 1/10 probability of falling. If these ladders are independent, the probability that two fall together is 1/100. Three falling together: 1/1000. The probability of all 100 falling simultaneously becomes astronomically small – negligible, essentially zero.
Now tie all the ladders together with rope. You’ve made any individual ladder safer (less likely to fall on its own), but you’ve created a non-negligible chance that all might fall together.
This is cascade risk in interconnected systems.
Two Types of Risk
From a society’s perspective, we can understand risks as falling into one of two categories:
Modular risks (thin-tailed) don’t endanger whole societies or trigger cascades. A traffic accident in Helsinki won’t affect Madrid or even Stockholm. These risks have many typical precedents, slowly changing trends, and are relatively easy to imagine. We can use evidence-based risk management because we have large samples of past events to learn from.
If something is present daily but hasn’t produced an extreme for 50 years, it probably never will.
Cascade risks (fat-tailed) pose existential threats through domino effects. Pandemics, wars, and climate change fall here. They’re abstract due to rarity, with few typical precedents – events tend to be either small or catastrophic, with little in between.
If something hasn’t happened for 50 years in this domain, we might have just been lucky, and it might still hit us with astronomical force.
Consider these examples:
Workplace injuries
Street violence
Non-communicable diseases
Nuclear plant accidents
Novel pathogens
War
Before reading on, give it a think. Which are modular? Which are cascade risks?
I’d say most workplace injuries and street violence are modular (unless caused by organised crime or systemic factors like pandemics). Non-communicable diseases are also modular, although can be caused by systemic issues. Mega-trends perhaps, but you wouldn’t expect a year when they suddenly doubled, or became 10-fold.
Novel pathogens and wars are cascade risks that spread across borders and trigger secondary effects. These are the ladders tied together with a rope. Nuclear plants kind of depend; nowadays people try to build many modular cores instead of one huge reactor, so that failure of one doesn’t affect the failure of others. But as the mathematician Raphael Douady put it: “Diversifying your eggs to different baskets doesn’t help, if all the baskets are on board of Titanic” (see Fukushima disaster).
Is That a Heavy Tail, or Are You Just Happy to See Me?
Panels A) and B) below show pandemic data (data source, image source, alt text for details) – with casualties rescaled to today’s population. The Black Death around the year 1300 caused more than 2.5 billion deaths in contemporary terms. Histograms on the right show the relative number of different-sized events. The distribution shows tons of small pandemics and a few devastating extremes, with almost nothing in between (panel A, vertical scale in billions). We see a similar shape even when we get rid of the two extreme events (panel B, vertical scale in millions).
Compare this to Panel C), Finnish traffic fatalities. Deaths cluster together predictably. You wouldn’t expect 10 000 road deaths in a single year – even 2 000 would be shocking.
Moving from observations to theory: The figure below compares mathematical “heavy-tailed” distributions to “thin-tailed” distributions. Heavy-tailed distributions depict:
Many more super-small events than thin-tailed distributions: Look at the very left side of the left panel below, where red line is above the blue one
Fewer mid-size events: Look at the middle portion of the left panel below, where blue line is higher than red
Extreme events of a huge magnitude that remain plausible: Look at the inset, which zooms into the tail (in thin-tailed distributions, mega-extremes are practically impossible like the ladders without a rope)
When we look at the right panel of the image above, thin-tailed distributions (like traffic deaths) should drop suddenly when plotted on a logarithmic scale. Fat-tailed distributions (like pandemics) should create a straight line, meaning very large events remain statistically plausible.
Or, at least that’s the theory, based on mathematical abstraction. Let’s see what the real data shows.
And here we go: The tail of actual pandemics looks like a straight line, while the tail of traffic deaths curves down like an eagle’s beak. Pretty neat, huh?
Evidence Lives in the Past, Risk Lives in the Future
In the interests of time, I’m going to skip a visualisation you see in the video (26:45). Main point is that for thin-tailed modular risks, we extrapolate from past data. For heavy-tailed cascade risks, we must form plausible hypotheses from current, weak, and incomplete signals.
This is the difference between induction (everything that happened before has these features, so future events will too) and abduction (reasoning to the most sensible course of action given limited information). All data is data from the past, and if the past isn’t a good indicator of the future, we need different ways of acting:
The mantra of resilience is early detection, fast recovery, rapid exploitation. – Dave Snowden
We need to detect weak signals early. The longer we wait, the bigger the destruction.
A Practical (piece of a) Solution: Participatory Community Surveillance Networks
In our research group, we’re developing networks of trusted survey respondents who participate regularly (see article), akin to the idea of “citizen sensor networks” also presented in the EU field guide Managing complexity (and chaos) in times of crisis. With such a network in place, during calm times, you can collect experiences and feedback on policy decisions. When crisis hits, you can pivot to gain rich real-time data from the field.
Why? Because nobody can see everything, and we see what we expect to see. If you don’t believe me, see if you can solve this mystery.
Given enough eyeballs, all bugs are shallow – Eric S. Raymond
The process:
Set up a network of trusted responders
Collect experiences continuously
Pivot when crisis takes place to gather data on how the disruption shows up in lived experience
Avoid the trap of post-emergency mythmaking, and do a “lessons learnt” analysis with data collected during the disruption
Example: Inhabitant Developer Network
We developed an idea in a Finnish town, where new inhabitants would join the network as part of a “welcome to town” package. We could ask:
“What’s better here than where you lived before?” → relay to marketing
“What’s worse here than where you lived before?” → relay to development
When crisis occurs, we could pivot, asking about how the disruption shows up in people’s lived experience:
“What happened?”
“Give your description a title”
“How did this affect things important to you?”
“How well did you do during and after?” (1-10 scale)
“How prepared were you?” (1-10 scale)
… etc.
Respondents self-index these experiential snippets with quantitative indicators, giving us both qualitative richness and quantitative patterns. We can then e.g. examine situations where people were well-prepared but didn’t do well, or did well despite being unprepared – and filter e.g. by tags like rescue service involvement. This gives us rich data from the field to inform local decision makers.
From Experiences to Action
The beauty of collecting people’s lived experience is that they can later be used for citizen or whole-of-workforce engagement workshops. You can ask Dave Snowden’s iconical question: “How could we get more experiences like this, and fewer like those?”
This question holds an outcome “goal” lightly, allowing journeys to start with direction rather than rigid destination. It is understandable regardless of education level, and gives communities agency in developing solutions. This approach enables:
Anticipation: Use tailedness analysis as a diagnostic; use networks to detect weak signals before they explode.
Formulation: Design adaptive interventions with the community – interventions that are change instead of being fragile to the first unexpected shock.
Adoption: Build agency, legitimacy and buy-in through participatory processes. People support what they own or help create.
Implementation & Evaluation: Monitor in real-time, learn continuously, act accordingly. No more waiting six months for a report, or getting a quantitative result (“life satisfaction fell from 3.9 to 3.2”) only to need another research project to learn why: You can just look at the qualitative data to understand context.
Why This Matters
When Red Eléctrica declared “there exists no risk,” they were thinking in a thin-tailed world where past data predicts future outcomes. But interconnected systems – like them tied-together ladders – create heavy-tailed risks. For cascade risks, precaution matters more than proof. If you face an existential risk and fail, you won’t be there to try again.
As Nassim Nicholas Taleb puts it: Risk is acceptable, ruin is not (more in this post). And no individual human is capable of understanding our modern, interconnected environments alone.
For deeper exploration of these concepts, I recommend Nassim Nicholas Taleb’s books: Fooled by Randomness, The Black Swan, and Antifragile, as well as the aforementioned EU field guide Managing complexity (and chaos) in times of crisis.
New perspectives from my doctoral research, “Complex Systems and Behaviour Change: Bridging Far Away Lands.”
On May 16, 2025, I finally defended my doctoral dissertation – a side-project in the making for the last 9 years or so. I was pretty confident that this would have happened two years ago already when I submitted a rogue version of the dissertation summary for pre-examination. It was titled “Understanding and Shaping Complex Social Systems: Lessons from an emerging paradigm to thrive in an uncertain world”, which is also the name of a course I later started teaching in the New England Complex Systems Institute. The preprint was quickly downloaded almost 1000 times, and people reached out to me to thank for the clear exposition. But this version turned out to be a bit too rogue for one of the pre-examiners, and I rewrote the whole thing in 2024 – to be much more technical, and stylistically more conventional.
The defence was a success and here we are, the dissertation finally accepted by the academic establishment. Published summary can be downloaded here. The implicit promise is that after reading the work, you’ll be able to understand this cartoon, which you might recognise to have a relationship with the cover image:
As is traditional in the Finnish system, I began the occasion with a Lectio Praecursoria – an introductory speech. This talk introduced the groundwork for my research, exploring the often-overlooked connections between two seemingly distant scientific fields: complex systems and behaviour change.
This blog post adapts that initial speech, inviting you to explore these ideas with me.
The Core Idea: Why We Need to Rethink Behaviour Change
The research I present explores the intersection of two scientific domains that might seem, at first glance, quite distant. But what I want to do is share why building bridges between complex systems and behaviour change is not merely an academic curiosity, but, as I argue in this work, a vital step towards deepening our understanding of human action in our increasingly interconnected world, and ultimately, towards building a more robust basic science of behaviour change. [Side note: you can find my perspective to what behaviour change is NOT here, and connections to risk management here and here.]
The “Fruit Salad vs. Bread” Analogy: Understanding Different Types of Systems
To begin, let us talk about the difference between making fruit salad and baking bread. I am well aware of how ludicrous this sounds, but I believe that confusing these two processes consistently causes well-meaning efforts, particularly those aimed at changing behaviour, to stumble. So please bear with me.
Imagine making fruit salad for a bunch of children. You gather fruits you enjoy – perhaps pineapple, peach, and cherries. You’re fairly confident that if you like them separately, you’ll like them together. You chop them, combine them, and serve them. Now, if a child finds that cherries look too strange to be edible – and leaves them behind – it’s no catastrophe. They can still consume the pineapple and peach, which every reasonable person enjoys. The uneaten cherries can be consumed by someone else later. In fruit salad, we can combine ingredients, analyse the parts somewhat independently, and predict the outcome of the whole with reasonable certainty. With many ingredients, fruit salad can become complicated – a word whose origins (as pointed out by Dave Snowden) can be taken to mean “folded.” And what has been folded, can often also be unproblematically unfolded.
Now, think about baking bread. You combine yeast, flour, water, and salt. You’ve heard that olive oil is healthy, so you add a bit of that in. You mix, knead, let it rise, bake. The final loaf emerges. But what if the children dislike the taste of olive? You cannot simply remove the oil. Or what if you put in too much salt? The ingredients have interacted, transformed. The bread is an emergent product, something entirely new, fundamentally different from the mere sum of its parts. The whole portion intended for the children, not just the offending component, might have to be passed to an omnivorous family member. This process is better described not as complicated, but as complex, a word with roots that can be interpreted as “entangled” or “interwoven.”
Unlike with folding, what is interwoven cannot easily be disentangled without fundamentally changing its nature.
The Two Key Disciplines: Behaviour Change and Complex Systems
With this analogy in mind, let’s turn to the disciplines central to my research.
Behaviour change science is an inherently interdisciplinary field drawing from psychology, sociology, public health, and more. It strives to understand the web of factors – personal, social, environmental – that shapes our actions. Its goal is to help foster changes needed to tackle major societal challenges: from noncommunicable diseases (entailing, for example, physical activity behaviours) and sustainable work-life (entailing, for example, job crafting behaviours) to climate action and pandemic preparedness (entailing risk management behaviours). Human action is a core thread in all these pressing issues.
The other discipline central to this work is complex systems science. It originally grew out of physics, chemistry, and biology, but its principles increasingly reach into the psychological and social world. It studies systems composed of many interacting parts, where these interactions often dominate the system’s overall behaviour. A key insight is that the relationships between components can be more critical than the components themselves in determining the system’s properties. Think of water: ice, liquid, and steam involve the same H₂O molecules, but their differing interconnectivity leads to vastly different behaviours. Steam can make a sauna feel warm; ice can make swimming difficult afterwards. But the components remain the same.
Are We Using Fruit-Salad Tools for Bread-Like Problems?
When it comes to systems, some are more component-dominant, like fruit salad, while others are more interaction-dominant, like bread. My research argues that many phenomena central to behaviour change science – like motivation dynamics, the spread of social norms, or how people respond to interventions – are far more like bread than fruit salad. They occur as parts of complex, interaction-dominant systems.
The main contributions of my dissertation relate to the development of basic science. Early theories in behaviour change were driven by practitioners aiming to understand issues they faced. And practitioners are often very good at working with complexity, although their terminology to describe the phenomena at play might sometimes be limited. But still, many of the quantitative tools that were relied upon in developing these theories implicitly treated behaviour change phenomena like fruit salad. For instance, while linear regression analysis can incorporate simple interaction terms to account for some forms of interdependence, its main usage is to assign values to variables such as norms, intentions, and attitudes, assuming they are independent from each other – implying separability. Furthermore, there’s a common, often implicit, assumption that findings derived from group-level data directly translate to understanding how individuals change over time.
So, the central question becomes: If behaviour change is often entangled and emergent like bread dough, should our primary tools be those best suited for slicing separable fruit?
Beyond Linearity: Embracing the Complexity of Change
I argue that this potential mismatch – analysing bread with fruit salad tools – can hinder our understanding of behaviour change as a complex evolving process. Complex systems science suggests that variability, which might look like messiness or error from a purely linear perspective, is often not just noise; it can be the inherent signature of the dynamic system itself.
A key characteristic of these systems, which I investigated conceptually and empirically, is non-linearity. Imagine pushing a boulder near a hilltop:
You push a little, the boulder moves a little.
You push a little, the boulder moves a little.
You push a little… and the boulder tumbles dramatically into a new valley.
Perhaps now scientists rush to the scene to investigate what was distinct in your technique for the last push. And they will inevitably find results. But the magic was not in the push, but the relationship between the push, the boulder’s position, and the landscape. This kind of abrupt, disproportionate change is known as a critical transition.
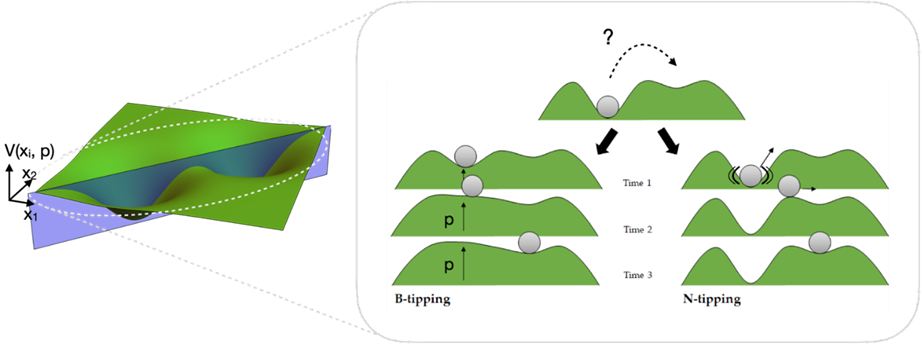
Mapping Change: The Power of Attractor Landscapes
Complex systems science offers a powerful conceptual tool to map transition dynamics: the attractor landscape. Imagine a pool table with a single billiard ball. Each position on the table represents a possible state for the system, and the current status is represented by the location of the billiard ball. Now imagine the surface isn’t flat, but contains hills and valleys. The valleys represent stable patterns – the attractors, collections of similar states that “trap” the ball. It’s easy for the ball to settle into a valley; it requires more effort or perturbation to push it out. The ridges between valleys are called tipping points.
A slice of an attractor landscape showing two major ways systems can shift abruptly (from an article included in the dissertation)
Think of smoking, where dispositions in the North Atlantic world shifted gradually if at all for many decades. Imagine this as a landscape: one valley where smoking is socially acceptable, and another where it is frowned upon. There was little change for a long time, until a tipping point was reached, leading to widespread disapproval and significant policy changes. Pushing the system over the ridge requires effort or a significant nudge, but once crossed, it naturally settles into a new attractor valley, a new stable pattern. However, this landscape isn’t necessarily static; it can transform and be reshaped. Think of this like the hills and valleys of the pool table rising and falling over time.
Notice how different this landscape representation is from conventional flowcharts suggesting neat, linear causes and effects. It shifts focus towards understanding the system’s dispositions, its underlying tendencies and stabilities. It encourages a focus on nurturing the conditions, tending the substrate, working the soil, from which desired behaviours – in deeper, more stable valleys – can emerge, and sustain themselves more naturally.
Evidence in Action: From Work Motivation to Public Health
In my research, I used analytical techniques adapted from dynamical systems theory to investigate empirical evidence for such attractor states and shifts within fine-grained, moment-to-moment work motivation data. I also explored its applicability to societal-level data on COVID-19 protective behaviours. This work suggests the landscape metaphor is not just a useful theoretical vehicle; these patterns can be observed and studied in real-world behaviour change contexts.
In addition to non-linearity, some of the patterns of complex systems I examined in this research were “non-stationarity” and “non-ergodicity”. In my work, I clarify these terms in the behaviour change context and demonstrate how to study them empirically in time series data, with methods such as cumulative recurrence network analysis.
The Key Takeaway: Complexity as a Feature, Not a Bug
In essence, the core message of this work is that the bread-like complexity of human behaviour change isn’t just noise or a problem to be simplified away. It’s a fundamental characteristic we must embrace and understand scientifically if we want our science to accurately reflect the phenomena it studies. Complex systems science provides concepts and tools that acknowledge interdependence, emergence, and context-sensitivity of change phenomena. And we aim not to eliminate this complexity, but to enlist it.
Looking Ahead: Building a Bridge to a More Robust Science of Human Action
By building bridges between behaviour change science and complex systems science, the research presented here argues that a complex systems perspective can help us build a more robust and realistic science of human action – one that recognises behaviour not just as a collection of separable ingredients like a fruit salad, but as an emergent, interwoven process like baking bread.
This, I believe, is crucial. It is crucial for developing a science better equipped to understand the intricate dynamics of behaviour change. It is crucial for us to seize the opportunities that arise when we learn to converse with complex systems, instead of just trying to push them around. And it is crucial for navigating the critical policy challenges of our time, which invariably involve understanding and enabling human action.
What are your thoughts? Leave a comment or reach out. My current research interests mainly revolve around risk management (see paper described here) – particularly, understanding and shaping communities’ capacities to respond, recover, and adapt from shocks. I’m a 72hours.fi trainer, and would be happy to collaborate in e.g. projects to make the EU’s new preparedness strategy a feasible reality.
Picture of me doing a sound check before the doctoral defense. It was held in Zoom as I was in Germany, the chair was in Finland, and the opponent in the U.S. 😅
I’ve recently followed with interest Dave Snowden’s development of “Estuarine Mapping”, also known as “Affordance Mapping”. The process is based on a complex systems framework to design and de-risk change initiatives (see link in the end of this post). After taking part in training sessions and facilitating some mapping exercises with groups, I found myself in want of a metaphor that didn’t require an understanding of coastal geography.
Enter the world of children’s parties. Snowden has a famous anecdote about organising a party for kids, which brilliantly illustrates the folly of applying traditional management techniques to complex systems. Inspired by this tale, I’ve reimagined it here as a simplified depiction of the Affordance Mapping process. So here we go.
Picture yourself tasked with organising a birthday bash for a group of energetic seven-year-olds. But instead of reaching for a conventional party-planning checklist, you decide to employ the Affordance Mapping process. What would you do?
First, you’d start by surveying the party landscape. You’d identify all the elements that could influence the party – from the near-immovable dining table to the ever-shifting moods of the kids. We’ll call these our party elements.
Next, you’d create a map of these elements. On one axis, you’d have how much energy it takes to change each element – moving the dining table would be high energy, while changing the music playlist would be low. On the other axis, you’d have how long it takes to make these changes – getting pizza delivered, or setting up a bouncy castle might take an hour, while changing a game rule could be instant.
Now, you’d draw a line in the top right corner. Everything above this line is beyond your control – things you absolutely can’t change, like the fact that Tommy’s allergic to peanuts. You’d also draw a second line for things that are outside your control, but amenable in collaboration with other parents, like how the party should end by 6 PM. You’d also mark a zone in the bottom left corner, for elements that change too easily and might need stabilising, like the kids’ attention spans or the volume level.
The result might look something like this:
The exciting part is the middle area. Here’s where you can actually make changes to improve the party; the things you can manage. But you can also try to make some elements more manageable via (de)stabilisation efforts, or remove some altogether.
For example, you might decide to:
Keep some elements as they are (the classic musical chairs game)
Remove others that aren’t fun (the complicated crafts project your spouse found on Pinterest)
Modify some to make them more enjoyable (have kids organise themselves into a line arranged by height, when moving outdoors after the cake is done with)
You’d come up with small experiments to test these ideas. Maybe you’ll try introducing a new party game like “freeze dance” to alleviate boredom in waiting for transitions from one activity to the next, or rearranging the gift-opening area. You’d also think about how changing one element might affect others – will having a water balloon toss right before snack time lead to damp clothes?
Finally, you’d plan how to amplify emergent positive side-effects, and mitigate negative ones. You’ll also redraw your party map before next year’s party. This way, you’re always working towards a more fun and dynamic party, understanding that some elements will always be shifting (like the kids’ favorite songs) while others stay constant (like the need for cake).
Technical note. The items on the map, in the lingo of the complex systems philosopher Alicia Juarrero, represent “constraints“; things that modulate a system’s behaviour. In complex systems, these are intertwined in such deep ways, that their effects are seldom amenable to an analysis of linear causality. To change a system’s macro-level state, you execute multiple parallel micro-interventions that aim to affect these constraints. For a recent open access book chapter outlining the rationale, see here: As through a glass darkly: a complex systems approach to futures.
Ilmahygieniaa koskeva tiede on edennyt valtavin harppauksin viime vuosina. Tämä sivu sisältää Suomen Akatemian kriisinkestävyyden ja huoltovarmuuden tutkimusrahoituksesta tuotetun Citizen Shield – Kansalaissuoja -hankkeen materiaaleja. Olen tuottamassa näitä monitieteellisessä yhteistyössä eri alojen osaajien kanssa, ja näet alla ensimmäisen version. Olet aloitussivulla, ja muut sivut löydät täältä:
Muistatko, kun elokuvateattereissa ja busseissa sai tupakoida vapaasti? Nyt moinen tuntuisi omituiselta. Onkin todennäköistä, että 20 vuoden päästä ihmetellään, miten tunkkaisissa ja huonon ilmanlaadun tiloissa suomalaiset jaksoivat toimia vielä 2020-luvulla. Jokaiselle on keinoja parantaa sisäilman laatua.
Mistä tiedän, onko ilmanvaihto riittävää? Miten mitoittaa ilmanvaihto niin, että se on riittävää tautien leviämisen vähentämiseksi? Tautien leviämisen ehkäisemiseksi ilmanvaihto on hyvä mitoittaa oikein. Jos koneellinen ilmanvaihto ei ole riittävää, sitä voidaan täydentää ilmanpuhdistimilla.
Keinot ilmanlaadun parantamiseen eivät välttämättä vaadi erillisiä hankintoja. Voit ottaa keinoja käyttöön riippumatta asumismuodostasi. Ilmanvaihdon ja -puhdistuksen hyödyt turhien sairastumisten ehkäisyssä perustuvat tutkimukseen. Turhat sairastumiset tuottavat harmia monille. Siksi…
Esimerkiksi influenssa ja koronavirus leviävät ilmateitse. Asiakkaiden turvallisuus mietityttää. Puhdas sisäilma voi olla myös kilpailuvaltti! Belgiassa tulee voimaan lainsäädäntö, jonka mukaan julkisissa tiloissa tulee mitata ja viestiä asiakkaille ilmanlaadusta. Nyt on mahdollisuus olla edelläkävijä!
Tutkimustiedon karttuessa, myös nämä tiedot saattavat edelleen päivittyä. Eräs näiden sivujen tarkoitus on altistaa materiaaleja yhteiskunnallisen parviälyn huomioille. Kommentit ja kehitys-/korjausehdotukset voi osoittaa minulle!
Ilmahygieniaa koskeva tiede on edennyt valtavin harppauksin viime vuosina. Tämä sivu sisältää Suomen Akatemian kriisinkestävyyden ja huoltovarmuuden tutkimusrahoituksesta tuotetun Citizen Shield – Kansalaissuoja -hankkeen materiaaleja. Olen tuottamassa näitä monitieteellisessä yhteistyössä eri alojen osaajien kanssa, ja näet alla ensimmäisen version. Löydät muut sarjan sivut täältä ja tästä:
Tutkimustiedon karttuessa, myös nämä tiedot saattavat edelleen päivittyä. Eräs näiden sivujen tarkoitus on altistaa materiaaleja yhteiskunnallisen parviälyn huomioille. Kommentit ja kehitys-/korjausehdotukset voi osoittaa minulle!
Miksi ilmanvaihto ja -puhdistus? Terveempää arkea pienillä teoilla
Muistatko, kun elokuvateattereissa ja busseissa sai tupakoida vapaasti? Nyt moinen tuntuisi omituiselta. Onkin todennäköistä, että 20 vuoden päästä ihmetellään, miten tunkkaisissa ja huonon ilmanlaadun tiloissa suomalaiset jaksoivat toimia vielä vuonna 2020-luvulla. Jokaiselle on keinoja parantaa sisäilman laatua, ja listaamme alempana eri tahoille soveltuvia tapoja.
Koronapandemian myötä puhtaan sisäilman merkitykseen on havahduttu aivan uudella tavalla. Koronavirus ja influenssa leviävät merkittäviltä osin ilmavälitteisesti. Nämä taudit leviävät, kun hengitämme toisen keuhkoissa ollutta ilmaa. Ilmanvaihto ja -puhdistus ovat hengityssuojainten lisäksi tehokkaita keinoja torjua tartuntoja. Tällä sivustolla keskitymme näistä ensimmäisiin; hengityssuojaimista voit lukea lisää tästä katsauksesta tai tuottamistamme ohjeista.
Ilmavälitteisesti leviäviä tauteja ovat myös esimerkiksi tuberkuloosi, tuhkarokko ja vesirokko (ks. CDC, WHO). WHO ja CERN ovat tuottaneet tällaisten tautien torjuntaa helpottavan riskiarviotyökalun.
Kokosimme ajankohtaista tietoa ilmahygienian hyödyistä. Kuka tahansa voi ottaa keinoja käyttöön niin vuokra- tai omistusasujana sekä työpaikalla, harrastuksissa tai juhlissa.
Mitkä puhtaan sisäilman hyödyt ovat tärkeitä sinulle? ☐ Vähemmän sairauspoissaoloja työpaikalla tai koulussa ☐ Pienempi riski sairastua koronaan tai influenssaan ☐ Tehokkaampaa työntekoa ☐ Helpompaa oppimista ☐ Virkeämpi olo ☐ Vähemmän päänsärkyjä ☐ Vähemmän tunkkainen sisäilma
Mitä voimakkaammin tartuttava henkilö puhuu, yskii, aivastelee tai puuskuttaa, sitä enemmän hän tuottaa ilmaan virusta sisältäviä hiukkasia. Suurin osa näistä hiukkasista on pieniä aerosoleja. Ne kulkeutuvat tilassa samalla tavalla kuin tupakansavu mutta näkymättömänä ja hajuttomana.
Jos ilma ei vaihdu riittävästi, hiukkasia kertyy hengitysilmaan. Tällöin tartunnalle myös altistuu nopeammin.
Hiukkaset kulkeutuvat koko tilaan ja voivat pysyä ilmassa tunteja, vaikka tartuntariski onkin suurin lähellä tartuttavaa henkilöä.
Sairastumisen riski kasvaa, kun virusta sisältäviä hiukkasia hengittää enemmän, esimerkiksi oleilemalla tilassa pidempään.
Suojatoimet vähentävät riskiä kertautuvasti. Ottamalla käyttöön neljä toimenpidettä (esim. ilmanpuhdistus, ilmanvaihdon tehostaminen, altistusajan vähentäminen, sekä tilassa oleilevien henkilöiden määrän vähentäminen), joista kukin yksinään vähentäisi tartuntariskiä vain kolmanneksella, saavutettaisiin yli 80% alenema riskissä.
Mitä eroa on ilmanvaihdolla, ilmanpuhdistuksella ja ilmastoinnilla?
– Ilmanvaihdolla tarkoitetaan sisäilman korvaamista ulkoa tulevalla ilmalla ja epäpuhtauksien poistamista sisäilmasta. – Ilmanpuhdistuksella sisäilmasta poistetaan epäpuhtauksia. Mekaaninen ilmanpuhdistus (esim. HEPA- tai EPA-suodatus) on suositeltava puhdistusmenetelmä. Se ei tuota ilmaan haitta-aineita, kuten otsonia, toisin kuin otsonaattorit. – Ilmastoinnilla säädellään tulo- ja kierrätysilman ominaisuuksia, kuten lämpötilaa, kosteutta ja puhtautta.
Vuosittain pelkästään influenssaan sairastuu noin 10 % väestöstä 6–8 viikon aallon aikana. Näin ollen noin 0,55 miljoonaa sairastuisi, ja kolmen päivän poissaolo à 370€/pv tarkoittaisi 610M€ kustannuksia.
Virkeyttä ja työtehoa
Huonosta ilmanvaihdosta on myös muuta haittaa. Huono sisäilma voi johtaa alentuneeseen suorituskykyyn tietotyössä, mikä tarkoittaa esimerkiksi huonompaa havaitsemista ja tarkkaavuutta. Huono sisäilma voi myös lisätä väsymystä ja päänsärkyä.
Eräässä tutkimuskatsauksessa tarkasteltiin, millaisia vaikutuksia ilmanlaadulla on koulutyöstä suoriutumiseen. Tulosten mukaan parempi sisäilma voisi johtaa jopa:
12 % nopeampaan suoriutumiseen psykologisista testeistä ja koulutehtävistä
2 % pienempään määrään virheitä
2,5 % lisääntyneeseen läsnäoloon koulussa.
Toisin sanoen ilmanvaihdon toimivuus vaikuttaa ajatustyöhön, eli työtehoon niin toimistoissa kuin oppilaitoksissa. Siksi ilmanlaatuun panostamalla saadaan virkeämpää oloa arkeen.
COVID-19 -pandemia herätti päättäjät toimiin maailmalla
Koronapandemian aikana huomattiin, että hengitysteissä esiintyvät infektiot leviävät merkittävästi ilman välityksellä. Siksi päättäjät ympäri maailmaa ovat ryhtyneet edistämään puhtaampaa sisäilmaa usein toimin.
Yhdysvalloissa tartuntatautiviranomainen on laatinut ohjeistuksia erilaisista ilmanvaihtokeinoista, joilla voidaan vähentää tautien leviämistä. Ohjeistuksissa neuvotaan tuulettamaan, lisäämään ilmanvaihtoa ja ilmanpuhdistimen käyttämisestä.
AustraliassaViktorian osavaltiossa kouluihin on hankittu ilmanpuhdistimia. Lisäksi kouluja ohjeistetaan lisäämään ilmanvaihtoa esimerkiksi tuulettamalla, pitämään oppitunteja ulkona ja välttämään opetustiloja, joissa on huono ilmanvaihto. Näille ohjeille löytyy tukea tutkimuksesta: Italiassa kouluissa ilmanvaihtoa parannettiin ja sairastumiset koronavirustautiin vähenivät jopa 80 %.
Koulujen sisäilman hiilidoksiditasoja seurataan esimerkiksi Latviassa, Lybeckissä, Berkeleyssä, ja Bostonissa. Koulukohtaiset ilmanlaatutiedot ovat myös julkisesti näkyvillä.
Myös esimerkiksi Porissa koulun ilmanvaihtoremontin yhteydessä asennettiin järjestelmä, jolla mitataan ja seurataan hiilidioksidipitoisuutta.
Ilmahygieniaa koskeva tiede on edennyt valtavin harppauksin viime vuosina. Tämä sivu sisältää Suomen Akatemian kriisinkestävyyden ja huoltovarmuuden tutkimusrahoituksesta tuotetun Citizen Shield – Kansalaissuoja -hankkeen materiaaleja. Olen tuottamassa näitä monitieteellisessä yhteistyössä eri alojen osaajien kanssa, ja näet alla ensimmäisen version. Löydät muut sarjan sivut täältä ja tästä:
Tutkimustiedon karttuessa, myös nämä tiedot saattavat edelleen päivittyä. Eräs näiden sivujen tarkoitus on altistaa materiaaleja yhteiskunnallisen parviälyn huomioille. Kommentit ja kehitys-/korjausehdotukset voi osoittaa minulle!
Työkalut pandemiaturvalliseen ilmanvaihtoon
Mistä tiedän, onko ilmanvaihto riittävää?
Ilmanvaihdon arvioiminen kotikonstein
THL ja Sisäilmayhdistys ovat laatineet ohjeita siihen, kuinka ilmanvaihdon puutteita voi arvioida myös ilman erillisiä mittauksia. Merkkejä puutteellisesta ilmanvaihdosta ovat:
kosteuden hidas poistuminen kylpyhuoneessa
tunkkaisen tuntuinen ilma ja hajujen hidas poistuminen
paperiarkki ei pysy poistoilmaventtiilissä kiinni
kosteus tiivistyy lasipinnoille, kuten ikkunoihin
lingottu pyykki ei kuivu vuorokaudessa
saunomisen jälkeen tila ei ole kuivunut seuraavaan aamuun mennessä.
Löydät ilmanvaihdosta lisää käytännönläheistä tietoa Hengitysliiton Kodin sisäilma ja ilmanvaihto -oppaasta sekä THL:n sivuilta. Keväällä 2024 WHO ja CERN julkaisivat uuden riskilaskurin, jolla tilojen hallinnoijat ja käyttäjät voivat arvioida niiden tartuntatautiturvallisuutta.
Hiilidioksidipitoisuuden mittaaminen
Hiilidioksidia kertyy sisäilmaan hengityksen seurauksena, erityisesti kun ilmanvaihto on huono. Sisäilman laatua ja ilmanvaihdon riittävyyttä voi arvioida hiilidioksidimittarilla.
Kun mittari näyttää korkeaa lukemaa, ilmanvaihtoa voi lisätä esimerkiksi avaamalla ikkunan. Hiilidioksidimittareissa on eroja tarkkuudessa: NDIR-anturilla varustetut mittarit ovat suhteellisen luotettavia. Hiilidioksidimittarit voivat olla kooltaan pieniä, minkä vuoksi kuka vain voi käyttää niitä käyttämiensä tilojen ilmanvaihdon arvioimiseen.
Missä tilanteessa voin käyttää hiilidioksidimittaria?
Mittarilla voi seurata esimerkiksi harrastustilojen, kylätalon tai ravintolan ilmanvaihtoa, niin asiakkaana kuin yrittäjänäkin. Esimerkiksi ravintoloitsijana voit mitata sisäilman laatua, kohentaa sitä tarvittaessa ja kertoa toimistasi asiakkaille.
Joissain maissa hiilidioksidimittari ja sen lukema on näkyvissä asiakkaille esimerkiksi taksissa tai ravintolan seinällä.
Kun halutaan vähentää sairastumisia ilmavälitteisiin tauteihin, mittarin tulkinnan apuna voi käyttää REHVA-standardeja.
REHVA:n esimerkkilaskelmassa eräässä 25 henkilön luokkahuoneessa infektioturvallinen ilmanvaihto johti hiilidioksidipitoisuuteen 941 ppm. Ravintolaa kuvaavassa esimerkissä 154 asiakkaan tapauksessa turvallinen ilmanvaihto johti sen sijaan pitoisuuteen 486 ppm (Ravintola: pinta-ala 259,5 m2, huoneen korkeus 2,9 m, 154 henkilöä. Luokkahuone: pinta-ala 42,5 m2, huoneen korkeus 2,9 m, 25 henkilöä).
Muita standardeja ovat D2 Suomen Rakentamismääräyskokoelma ja Sisäilmastoluokitus. Sisäilmastoluokituksen erittäin hyvän luokituksen sisäilmassa hiilidioksidipitoisuus on alle 750 ppm. Näitä luokituksia ei kuitenkaan ole tehty ilmavälitteisten tautien näkökulmasta.
Nyrkkisääntö – mitä mittarin lukema tarkoittaa?
Hiilidioksiditaso (ppm)
Kuvaus
🔵 n. 400
Ilman hiilidioksidipitoisuus ulkoilmassa
🟢 <799
Hyvä ilmanvaihto
🟡 800-1499
Huono ilmanlaatu; uneliaisuutta ja isompi riski ilmavälitteisten tautien tarttumiseen. Sairastumista välttelevien kannattaa viimeistään nyt käyttää hengityssuojainta.
🔴 >1500
Riittämätön ilmanvaihto; voi johtaa huonompiin oppimistuloksiin ja ilmavälitteisten tautien tarttumiseen.
Miten mitoittaa ilmanvaihto niin, että se on riittävää tautien leviämisen vähentämiseksi?
Sisäilmayhdistyksen suositus parhaan S1-luokan mitoitusilmavirraksi on 0,5 l/s/lattia-m2 + 10 l/s /henkilö.
Tautien leviämisen ehkäisemiseksi ilmanvaihto voi olla hyvä mitoittaa suuremmaksi.
Jos koneellinen ilmanvaihto ei ole riittävää, sitä voidaan täydentää ilmanpuhdistimilla.
Lisätietoa ja työkaluja riittävän ilmanvaihdon laskemiseen ovat REHVA– ja ASHRAE 241 -standardit (sivustot englanniksi). Huomioi myös WHO:n riskilaskuri.
Esimerkki mitoituksesta päiväkodin tiloissa
– Päiväkotiryhmässä on 12 lasta ja 3 aikuista. – Ilmanvaihto nykyisellään on 7 l/s/hlö. – Jotta päästäisiin esimerkiksi 15 l/s/hlö tavoitteeseen, ilmanvaihtoa tulisi lisätä 8 l/s/hlö (15-7 = 8). – Ilmanpuhdistimen tulisi tuottaa lisää puhdasta ilmaa 432 CADR. Siispä tilaan pitäisi tuoda 1-3 ilmanpuhdistinta mallista riippuen. – Ilmanpuhdistinten kanssa on hyvä huomioida myös äänihaitta. Tavoitetasoon tulisi päästä ilman, että puhdistin tuottaa liian suurta melua.
Kuka voi tehdä mitäkin?
Kuka?
Mitä voisin tehdä?
Yksilö/ Kaikki
Tuuleta ikkunoita avaamalla, 5 minuuttia kerran tunnissa – huomioiden siitepölykausi ja katupöly.
Tehosta ilmanvaihtoa koneellisella poistolla, esimerkiksi liesituulettimella.
Käytä ilmanpuhdistimia, jotka suodattavat ilmasta epäpuhtauksia.
Käytä hiilidioksidimittaria.
Käytä hengityssuojainta (FFP2 tai FFP3; ks. myös ohjeistuksemme).
Ehdota näiden ilmahygieniatoimien käyttöön ottamista harrastuksissa, koulussa, työpaikalla tai kotijuhlissa.
Ilmahygieniaa koskeva tiede on edennyt valtavin harppauksin viime vuosina. Tämä sivu sisältää Suomen Akatemian kriisinkestävyyden ja huoltovarmuuden tutkimusrahoituksesta tuotetun Citizen Shield – Kansalaissuoja -hankkeen materiaaleja. Olen tuottamassa näitä monitieteellisessä yhteistyössä eri alojen osaajien kanssa, ja näet alla ensimmäisen version. Löydät muut sarjan sivut täältä ja tästä:
Tutkimustiedon karttuessa, myös nämä tiedot saattavat edelleen päivittyä. Eräs näiden sivujen tarkoitus on altistaa materiaaleja yhteiskunnallisen parviälyn huomioille. Kommentit ja kehitys-/korjausehdotukset voi osoittaa minulle!
4 + 1 keinoa parantaa sisäilman laatua – jokaiselle!
Keinot ilmanlaadun parantamiseen eivät välttämättä vaadi erillisiä hankintoja. Voit ottaa keinoja käyttöön riippumatta asumismuodostasi. Ilmanvaihdon ja -puhdistuksen hyödyt turhien sairastumisten ehkäisyssä perustuvat tutkimukseen.
Turhat sairastumiset tuottavat harmia monille. Siksi keinot puhdistaa ilmaa ja ehkäistä sairastumisia voivat olla tervetulleita ehdotuksia myös juhlissa, kuntosalilla ja työpaikalla. Tästä löydät ideoita, kuinka voit parantaa ilmanvaihtoa useissa tilanteissa.
Ilmanpuhdistin on laite, jolla voidaan poistaa sisäilmasta epäpuhtauksia ja hiukkasia, kuten pölyä, bakteereja ja aerosolihiukkasia. Ilmanpuhdistimilla ei voi korvata huonosti toimivaa ilmanvaihtoa. Ne eivät korjaa hometta tuottavia rakenteita tai lisää ilmaan happea.
Tuuletusajan ei tarvitse olla pitkä: ilma vaihtuu tehokkaasti ristivedon avulla. Erityisesti talvella lyhytkin tuuletus riittää. Suuremman lämpötilaeron vuoksi ilma vaihtuu sisä- ja ulkotilan välillä nopeammin.
Voit tehostaa ilman vaihtumista asettamalla tuulettimen puhaltamaan ulospäin avonaisesta ikkunasta. Älä aseta tuuletinta osoittamaan ihmisiä päin.
4. Ilman koneellisen poiston tehostaminen esimerkiksi liesituulettimella
Useissa tiloissa ilmanvaihtoa on mahdollista tehostaa. Yksi kotikonsti ilman koneellisen poiston tehostamiseksi on liesituuletin.
Jos sinulla käy vieraita, liesituulettimen päällä pitäminen tunnin verran heidän lähtönsä jälkeen auttaa poistamaan mahdollisesti jäljellä olevia virushiukkasia.
+1 Mitä tehdä, jos sisäilma kotijuhlissa, harrastuksessa, konserttisalissa tai näyttelyssä on huono?
Jos sisäilmaa ei ole mahdollista puhdistaa, sairastumisen riskiä voi pienentää hengityssuojainten käytöllä. Erityisesti FFP2- ja FFP3 -hengityssuojaimet suojaavat aerosolihiukkasilta. Suojaimen tulee istua kasvoilla tiiviisti. Katso lisäohjeita täältä. TTL:n sivuilla on kerrottu suojainten teknisistä ominaisuuksista.
Keinot sopivat moneen tilaan!
*Ota huomioon kunkin tilan omat ohjeistukset siitä, saako ikkunoita avata itsenäisesti.
Ilmahygieniaa koskeva tiede on edennyt valtavin harppauksin viime vuosina. Tämä sivu sisältää Suomen Akatemian kriisinkestävyyden ja huoltovarmuuden tutkimusrahoituksesta tuotetun Citizen Shield – Kansalaissuoja -hankkeen materiaaleja. Olen tuottamassa näitä monitieteellisessä yhteistyössä eri alojen osaajien kanssa, ja näet alla ensimmäisen version. Löydät muut sarjan sivut täältä ja tästä:
Tutkimustiedon karttuessa, myös nämä tiedot saattavat edelleen päivittyä. Eräs näiden sivujen tarkoitus on altistaa materiaaleja yhteiskunnallisen parviälyn huomioille. Kommentit ja kehitys-/korjausehdotukset voi osoittaa minulle!
Ilmanvaihto kunnossa? Kerro siitä asiakkaille!
Esimerkiksi influenssa ja koronavirus leviävät ilmateitse, minkä vuoksi asiakkaiden turvallisuus voi mietityttää. Puhdas sisäilma voi olla myös kilpailuvaltti!
Joissain maissa jo suositellaan, että julkisissa tiloissa tulee mitata ja viestiä asiakkaille ilmanlaadusta. Nyt on mahdollisuus olla edelläkävijä myös Suomessa!
Hanki hiilidioksidimittari ja seuraa, millainen sisäilman laatu on yrityksesi tiloissa. Reagoi huonoon sisäilmaan esim. tuulettamalla tai tehostamalla ilmanpuhdistusta (ideoita täällä).
Ilmahygieniaa koskeva tiede on edennyt valtavin harppauksin viime vuosina. Tämä sivu sisältää Suomen Akatemian kriisinkestävyyden ja huoltovarmuuden tutkimusrahoituksesta tuotetun Citizen Shield – Kansalaissuoja -hankkeen materiaaleja. Olen tuottamassa näitä monitieteellisessä yhteistyössä eri alojen osaajien kanssa, ja näet alla ensimmäisen version. Löydät muut sarjan sivut täältä ja tästä:
Tutkimustiedon karttuessa, myös nämä tiedot saattavat edelleen päivittyä. Eräs näiden sivujen tarkoitus on altistaa materiaaleja yhteiskunnallisen parviälyn huomioille. Kommentit ja kehitys-/korjausehdotukset voi osoittaa minulle!
Leviämistä hengitysilman kautta pienissä aerosolihiukkasissa.
Leviämistä hengitysilman kautta suuremmissa, pisaramaisissa hiukkasissa.
Leviämistä lentokoneessa matkustettaessa.
Millä tavoin ilmanvaihto vaikuttaa ajatustyössä suoriutumiseen?
Ei vaikuta millään tavalla.
Parempi ilmanvaihto vähentää virheitä.
Lisää työtehoa ja vähentää sairastumisia.
Miksi ilmanpuhdistimen lisäksi tarvitaan ilmanvaihtoa?
Ilmanvaihtoa tarvitaan, jotta laitteen suodattimet toimivat kunnolla.
Ilmanvaihtoa tarvitaan, jotta ilmassa on riittävästi happea. Ilmanpuhdistin ei lisää hapen määrää.
Ilmanvaihtoa ei tarvita, jos ilmanpuhdistin on käytössä
Milloin lyhytkin tuuletus riittää ilman vaihtamiseen?
Kylmällä säällä.
Sateella.
Aurinkoisella säällä.
Mitkä ovat merkkejä puutteellisesta ilmanvaihdosta?
Kosteuden nopea poistuminen kylpyhuoneessa.
Paperiarkki ei pysy poistoilmaventtiilissä kiinni.
Lingottu pyykki kuivuu nopeasti.
Miten voi pienentää sairastumisen riskiä kotijuhlissa, joissa sisäilma on huono?
Käyttämällä hengityssuojainta.
Sulkemalla ikkunat tiiviisti.
Sulkemalla liesituulettimen.
Miksi tiloissa, joissa on korkea hiilidioksidipitoisuus voi olla pandemiaturvallista, jos niissä on kiertoilma ja hyvä suodatus (esimerkiksi matkustajalentokone)?
Hiilidioksidi suojaa viruksilta
Korkean hiilidioksidipitoisuuden tiloissa ei voi olla pandemiaturvallista
Mikä on ilmanvaihdon tärkein tehtävä toimistorakennuksissa?
Varmistaa, että käyttäjät voivat säätää huonelämpötilaa mukavuusalueelleen.
Ylläpitää riittävää sisäilmaston tasoa, jotta työntekijät voivat työskennellä terveellisessä ympäristössä.
Luoda tilaan viilentävää ilmavirtausta
Oikeat vastaukset:
Mitä tarkoittaa tautien leviäminen ilman kautta?
a ja b. Leviämistä hengitysilman kautta pienissä aerosolihiukkasissa sekä suuremmissa, pisaroiden kaltaisissa hiukkasissa.
Taudit kuten influenssa ja korona, leviävät merkittäviltä osin ilman kautta. Tartunta voi tapahtua hengitysilman mukana kulkeutuvien hiukkasten kautta, jotka voivat sisältää viruksia. Pieniä hiukkasia syntyy hengittäessä ja kaiken kokoisia sitä enemmän, mitä enemmän puhumme, laulamme, puuskutamme tai yskimme.
Hiukkaset ja pisarat sisältävät samoja taudinaiheuttajia kuin hengitysteiden neste. Jos henkilöllä on hengitystieinfektio, nämä hiukkaset voivat tartuttaa muita.Tartuntariski on suurin lähellä tartuttavaa henkilöä. Pienet hiukkaset voivat kuitenkin leijua ilmassa pitkään ja aiheuttaa tartunnan samassa tilassa vielä tunteja tartuttavan henkilön poistumisen jälkeen. (Lisätietoa: 1, 2)
Millä tavoin ilmanvaihto vaikuttaa ajatustyössä suoriutumiseen?
b ja c. Lisää työtehoa ja vähentää sairastumisia. Ilmanvaihdolla voidaan vähentää hiilidioksidin, mahdollisten virushiukkasten ja epäpuhtauksien määrää sisäilmasta. Sillä on positiivinen vaikutus kognitiiviseen suoriutusykyyn, eli mm. muistamiseen, tarkkaavuuteen ja havaitsemiseen.
Miksi ilmanpuhdistimen lisäksi tarvitaan ilmanvaihtoa?
b. Ilmanvaihtoa tarvitaan, jotta ilmassa on riittävästi happea Ilmanpuhdistin poistaa ilmasta epäpuhtauksia, mutta ei tuota tilalle uutta hapekasta ilmaa.
Milloin lyhytkin tuuletus riittää ilman vaihtamiseen?
a. Kylmällä säällä. Esimerkiksi talvisin ilma vaihtuu nopeammin sisä- ja ulkotilan välillä. Tämä johtuu suuremmasta erosta lämpötiloissa. Tuuletusta voi tehostaa myös ristivedolla.
Mitkä ovat merkkejä puutteellisesta ilmanvaihdosta?
b. Paperiarkki ei pysy poistoilmaventtiilissä kiinni. Tämä voi olla merkki siitä, ettei ilmanvaihto toimi riittävällä teholla.
Miten voi pienentää sairastumisen riskiä kotijuhlissa, joissa sisäilma on huono?
a. Käyttämällä hengityssuojainta. Tiiviisti istuvat FFP2- ja FFP3-suojaimet ehkäisevät virusten leviämistä. Sisäilman poistamista voi tehostaa myös liesituulettimen käynnistämisellä ja ikkunoiden avaamisella.
Miksi tiloissa, joissa on korkea hiilidioksidipitoisuus voi olla pandemiaturvallista, jos niissä on kiertoilma ja hyvä suodatus (esimerkiksi matkustajalentokone)?
c. Epäpuhtaudet poistuvat hengitysilmasta suodattimissa Hiilidioksidin määrästä ei voi päätellä sitä, onko ilmassa viruksia. Hiukkasia voidaan suodattaa ilmasta, mikä vähentää myös mahdollisia virushiukkasia.
Mitä hiilidioksidimittarin avulla voi arvioida?
a. Ilmanvaihdon riittävyyttä Sisäilmaan vapautuu uloshengityksen mukana hiilidioksidia. Korkea hiilidioksiditaso viestii siitä, ettei ilma vaihdu tilassa riittävästi. Hiilidioksidimittari ei kerro esimerkiksi ilman viruspitoisuutta.
Mikä on ilmanvaihdon tärkein tehtävä toimistorakennuksissa?
b. Ylläpitää riittävää sisäilmaston tasoa, jotta työntekijät voivat työskennellä terveellisessä ympäristössä. Riittävä ilmanvaihto lisää virkeyttä ja työtehoa, sekä ehkäiseen sairastumisten riskiä.