
In this post, I try to present the intuition behind the fact that, when studying real effects, one usually should not expect p-values near the 0.05 threshold. If you don’t read quantitative research, you may want to skip this one. If you think I’m wrong about something, please leave a comment and set the record straight!
Recently, I attended a presentation by a visiting senior scholar. He spoke about how their group had discovered a surprising but welcome correlation between two measures, and subsequently managed to replicate the result. What struck me, was his choice of words:
“We found this association, which was barely significant. So we replicated it with the same sample size of ~250, and found that the correlation was almost the same as before and, as expected, of similar statistical significance (p < 0.05)“.
This highlights a threefold, often implicit (but WRONG), mental model:
[EDIT: due to Markus’ comments, I realised the original, off-the-top-of-my-head examples were numerically impossible and changed them a bit. Also, added stuff in brackets that the post hopefully clarifies as you read on.]
- “Replications with a sample size similar to the original, should produce p-values similar to the original.”
- Example: in subsequent studies with n = 100 each, a correlation (p = 0.04) should replicate as the same correlation (p ≈ 0.04) [this happens about 0.02% of the time when population r is 0.3; in these cases you actually observe an r≈0.19]
- “P-values are linearly related with sample size, i.e. bigger sample gives you proportionately more small p-values.”
- Example: a correlation (n = 100, p = 0.04), should replicate as a correlation of about the same, when n = 400, with e.g. a p ≈ 0.02. [in the above-mentioned case, the replication gives observed r±0.05 about 2% of the time, but the p-value is smaller than 0.0001 for the replication]
- “We study real effects.” [we should think a lot more about how our observations could have come by in the absence of a real effect!]
It is obvious that the third point is contentious, and I won’t consider it here much. But the first two points are less clear, although the confusion is understandable if one has learned and always applied Jurassic (pre-Bem) statistics.
[Note: “statistical power” or simply “power” is the probability of finding an effect, if it really exists. The more obvious an effect is, and the bigger your sample size, the better are your chances of detecting these real effects – i.e. you have bigger power. You want to be pretty sure your study detects what it’s designed to detect, so you may want to have a power of 90%, for example.]

To get a handle of how the p behaves, we must understand the nature of p-values as random variables 1. They are much like the balls in a lottery machine, with values between zero and one marked on them. The lottery machine of real effects has disproportionately more low (e.g. < 0.01) values on the balls, while the lottery machine of null effects contains a “fair” distribution of numbers on balls (where each number is as likely as any other). If this doesn’t make sense yet, read on.
Let us exemplify this with a simulation. Figure 2 shows the expected distribution of p-values, when we do 10 000 studies with one t-test each, and every time report the p of the test. You can think of this as 9999 replications with the same sample size as the original.

Now, if we would do just five studies with the parameters laid out above, we could see a set of p-values like {0.002, 0.009, 0.024, 0.057, 0.329, 0.479}, half of them being “significant” (in bold). If we had 80% power to detect the difference we are looking for, about 80% of the p-values would be “significant”. As an additional note, with 50% power, 4% of the 10 000 studies give a p between 0.04 and 0.05. With 80% power, this number goes down to 3%. For 97.5% power, only 0.5% of studies (yes, five for every thousand studies) are expected to give such a “barely significant” p-value.
The senior scholar, who was mentioned in the beginning, was studying correlations. They work the same way. The animation below shows, how p-values are distributed for different sample sizes, if we do 10 000 studies with every sample size (i.e. every frame is 10 000 studies with that sample size). The samples are from a population where the real correlation is 0.3. The red dotted line is p = 0.05.
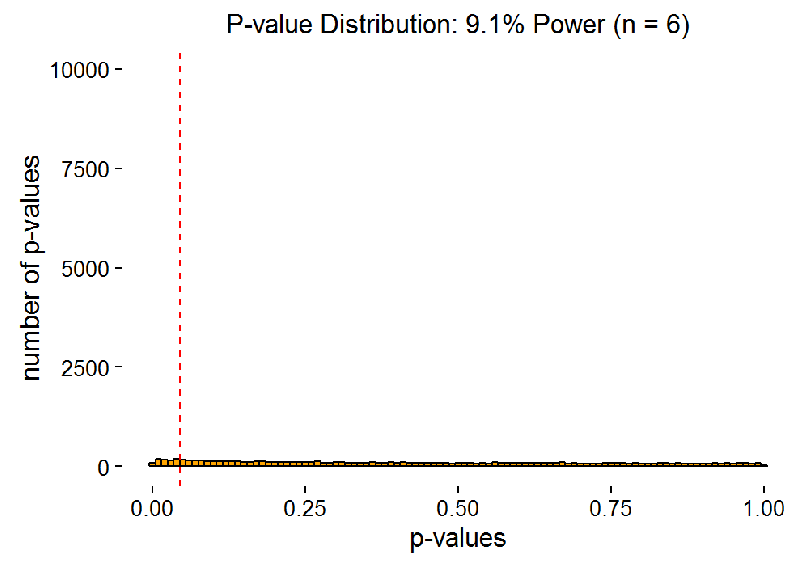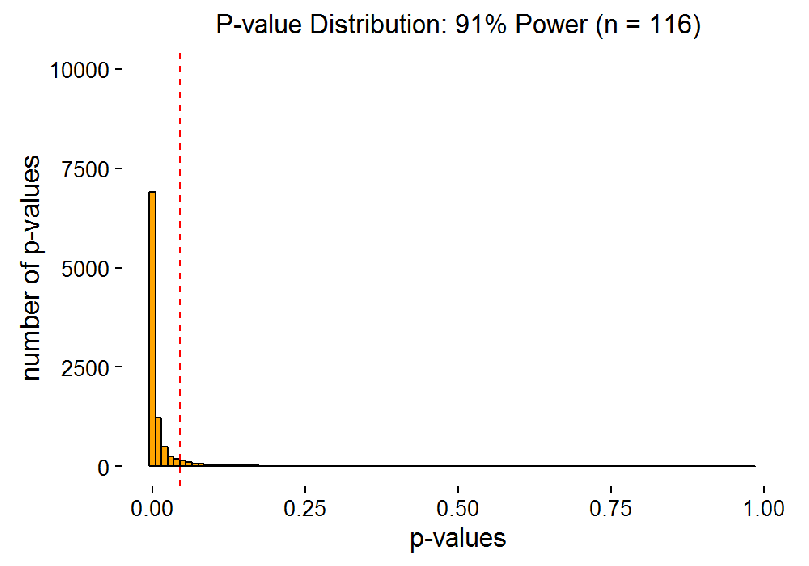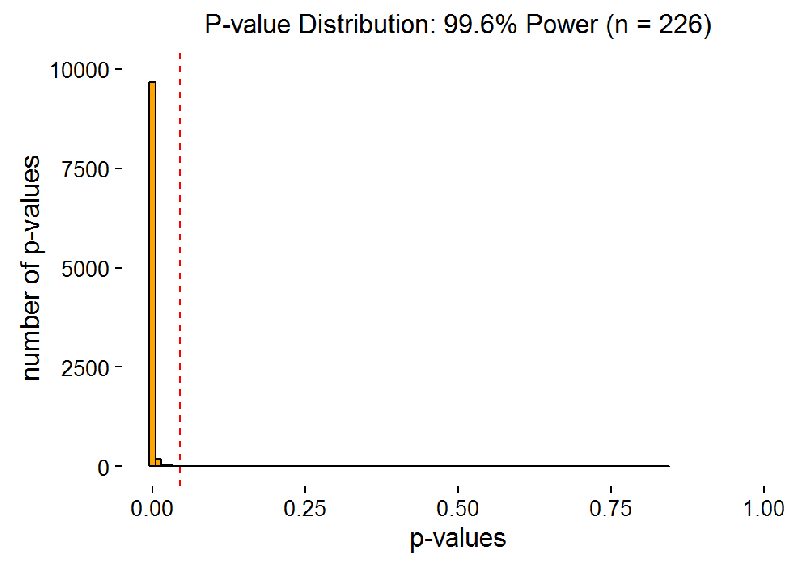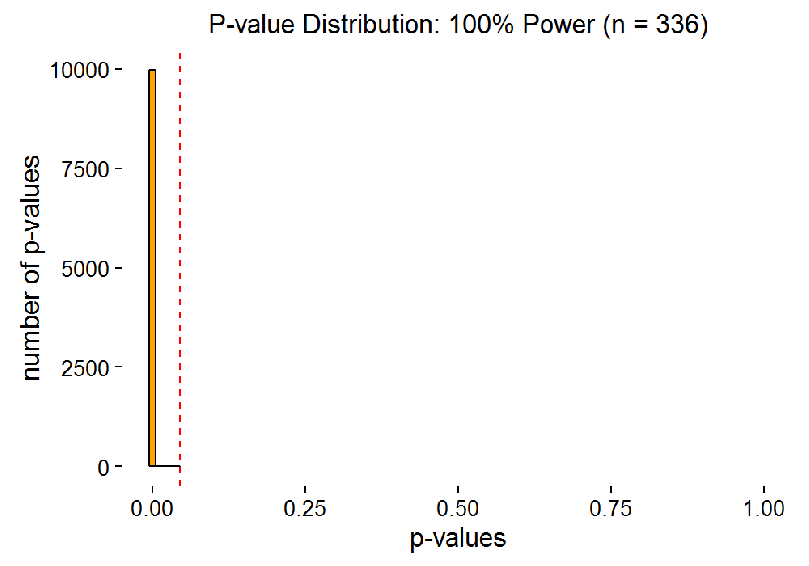
The next animation zooms in on “significant” p-values in the same way as in figure 2 (though the largest bar goes off the roof quickly here). As you can see, it is almost impossible to get a p-value close to 5% with large power. Thus, there is no way we should “expect” a p-value over 0.01 when we replicate a real effect with large power. Very low p-values are always more probable than “barely significant” ones.

But what if there is no effect? In this case, every p-value is equally likely (see Figure 5). This means, that in the long run, getting a p = 0.01 is just as likely as getting a p = 0.97, and by implication, 5% of all p-values are under 0.05. Therefore, the number of studies that generated a p between 0.04 and 0.05, is 1%. Remember, how this percentage was 0.5% (five in a thousand) when the alternative hypothesis was true under 97.5% power? Indeed, when power is high, these “barely significant” p-values may actually speak for the null, not the alternative hypothesis! Same goes for e.g. p=0.024, when power is 99% [see here].

Consider the lottery machine analogy again. Does it make better sense now?
The lottery machine of real effects has disproportionately more low (e.g. < 0.01) values on the balls, while the lottery machine of null effects contains a “fair” distribution of numbers on balls (each number is as likely as any other).
Let’s look at one more visualisation of the same thing:
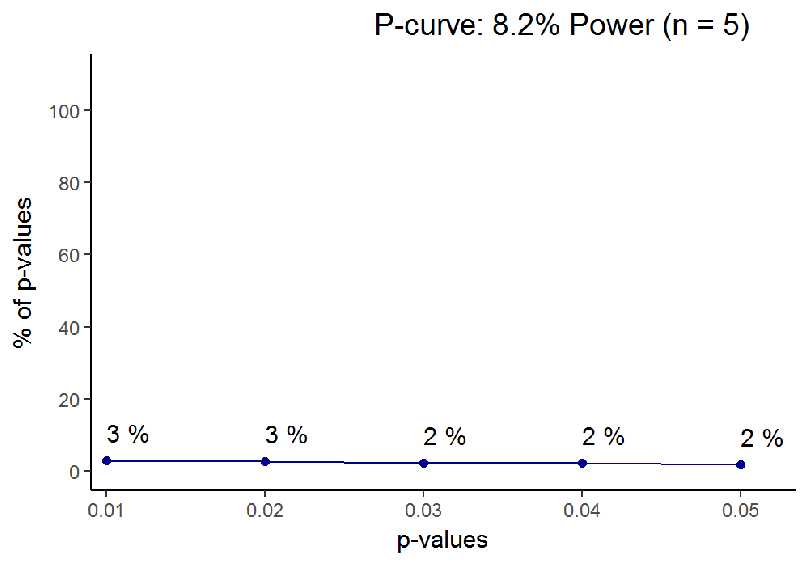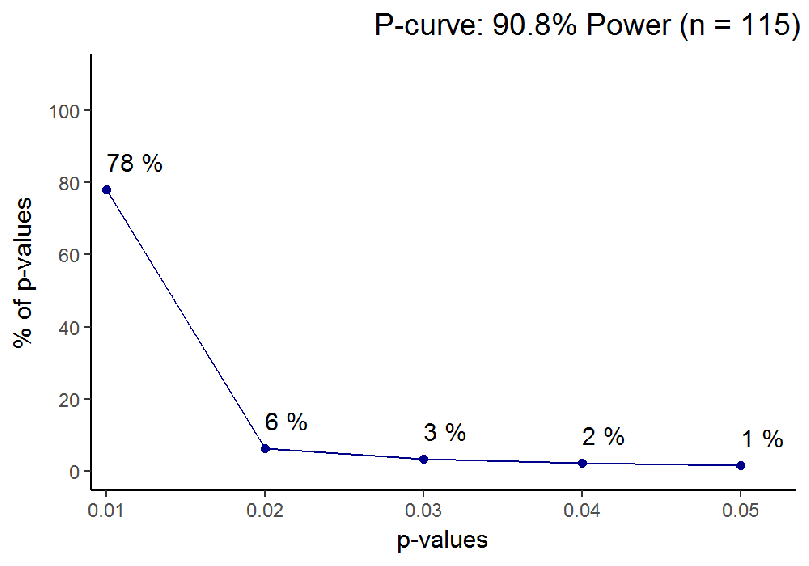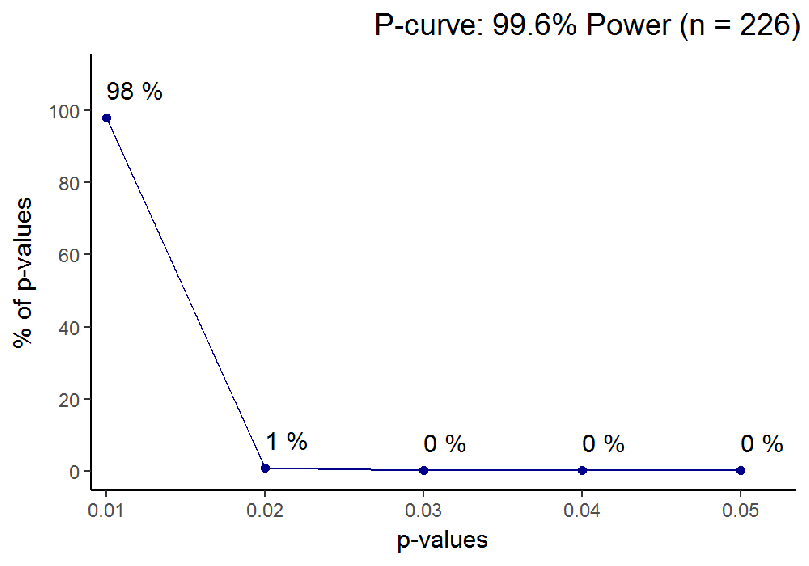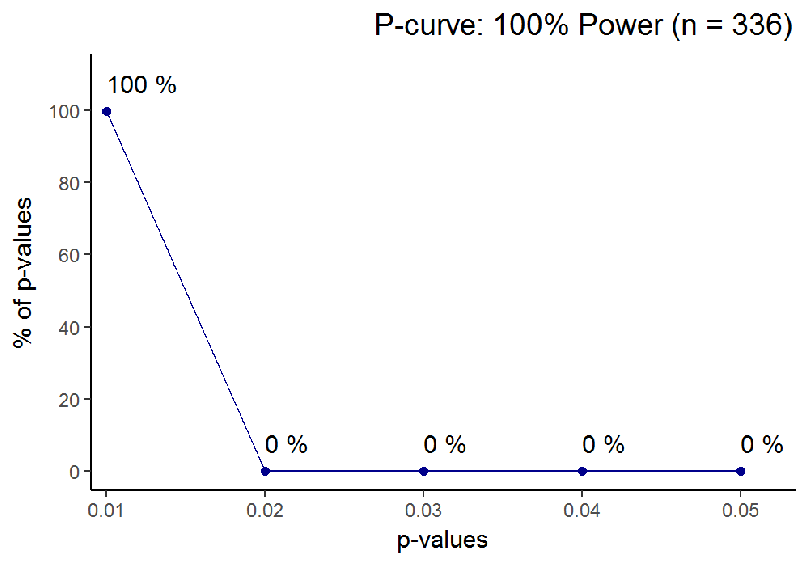
Aside: when the effect one studies is enormous, sample size naturally matters less. I calculated Cohen’s d for the Asch 2 line segment study, and a whopping d = 1.59 emerged. This is surely a very unusual effect size in psychological experiments, and leads to high statistical power even under low sample sizes. In such a case, by the logic presented above, one should be extremely cautious of p-values closer to 0.05 than zero.
Understanding all this is vital in interpreting past research. We never know what the data generating system has been (i.e. are p-values extracted from a distribution under the null, or under the alternative), but the data gives us hints about what is more likely. Let us take an example from a social psychology classic, Moscovici’s “Towards a theory of conversion behaviour” 3. The article reviews results, which are then used to support a nuanced theory of minority influence. Low p-values are taken as evidence for an effect.
Based on what we learned earlier about the distribution of p-values under the null vs. the alternative, we can now see, under which hypothesis the p-values are more likely to occur. The tool to use here is called the p-curve 4, and it is presented in Figure 6.

You can directly see, how a big portion of p-values is in the 0.05 region, whereas you would expect them to cluster near 0.01. The p-curve analysis (from the p-curve website) shows that evidential value, if there is any, is inadequate (Z = -2.04, p = .0208). Power is estimated to be 5%, consistent with the null hypothesis being true.
The null being true may or may not have been the case here. But looking at the curve might have helped researchers, who spent some forty years trying to unsuccessfully replicate the pattern of Moscovici’s afterimage study results 5.
In a recent talk, I joked about a bunch of researchers who tour around holiday resorts every summer, making people fill in IQ tests. Each summer they keep the results which show p < 0.05 and scrap the others, eventually ending up in the headlines with a nice meta-analysis of the results.
Don’t be those guys.

Disclaimer: the results discussed here may not generalise to some more complex models, where the p-value is not uniformly distributed under the null. I don’t know much about those cases, so please feel free to educate me!
Code for the animated plots is here. It was inspired by code from Daniel Lakens, whose blog post inspired this piece. Check out his MOOC here. Additional thanks to Jim Grange for advice on gif making and Alexander Etz for constructive comments.
Bibliography:
- Murdoch, D. J., Tsai, Y.-L. & Adcock, J. P-Values are Random Variables. The American Statistician 62, 242–245 (2008).
- Asch, S. E. Studies of independence and conformity: I. A minority of one against a unanimous majority. Psychological monographs: General and applied 70, 1 (1956).
- Moscovici, S. in Advances in Experimental Social Psychology 13, 209–239 (Elsevier, 1980).
- Simonsohn, U., Simmons, J. P. & Nelson, L. D. Better P-curves: Making P-curve analysis more robust to errors, fraud, and ambitious P-hacking, a Reply to Ulrich and Miller (2015). J Exp Psychol Gen 144, 1146–1152 (2015).
- Smith, J. R. & Haslam, S. A. Social psychology: Revisiting the classic studies. (SAGE Publications, 2012).

{kind=link}
[…] post by Heino Matti on false expectations about the relation between p values and sample size. Includes […]
LikeLike
Hmm. Did you consider that maybe after cautious review of the literature, researchers tend to select questions that are more likely to get publishable results?
LikeLike
Thanks for the comment! Can you elaborate a bit on what you mean and how would that affect the distribution?
LikeLike
Great post. Will read and re-read. ☺️
LikeLike
I don’t disagree with your points, but IMO you have the mental model wrong. I believe the assumption is, that 0.3 is the true correlation and per the significance test for correlations it is then merely a matter of sample size whether that correlation counts as significant or not.
1) It is reasonable to take the initial correlation as estimate of the population correlation and hence to expect a similar correlation in a subsequent study. (Of course, what counts as similar depends on power and theory.)
2) Given a similar correlation, it’s significance or not is merely a question of sample size. So, sure, if they find r = 0.3 again, using the same sample size, the p-value is also going to be similar.
Put differently, I’d argue the ‘as expected’ you highlighted in the quote is a conditional probability based on seing the similar correlation and thus merely reflects that the significance test for correlation will give you the same results if you apply it to two samples of identical size and with both r = 0.3.
There is certainly an element of underappreciated variation to the way these things are often talked about, and your wrong mental model certainly seems plausible. But for the example you describe it’s not the only and IMO not even the most likely explanation.
LikeLike
Hi Markus! I may misunderstand your point, so please correct me if I do. Let’s say a researcher miraculously hits the exact true point value correlation (0.3) in his sample of 110 (giving power of 85.5%), but due to fluctuation in the sampling, perceives a very large p-value (between 0.04 and 0.05*, where 2% of p-values land in this case). If the researcher then expects a similar correlation in a subsequent study, my point is that he should not expect a similar p-value – on the contrary, it is much more likely to see a small p with that correlation and sample size.
* We know this, because the researcher has said that p was “< 0.05"; had he perceived a smaller value, he would have claimed e.g. "p < 0.04", because this is a convention in psychology. Sorry, I only now realise this point was not obvious here.
If what we mean by “same results” is p < 0.05, you're certainly correct. But if we consider the possible unique values in the 0.00-0.05 area (say, to the second decimal), the same does not apply. I.e. the researcher should expect 0 < p < 0.05 but not the same 0.04 < p < 0.05, as he previously did. Would you agree?
LikeLike
” Let’s say a researcher miraculously hits the exact true point value correlation (0.3) in his sample of 110 (giving power of 85.5%), but due to fluctuation in the sampling, perceives a very large p-value (between 0.04 and 0.05*, where 2% of p-values land in this case)”
How is this supposed to work? The standard deviations are part of the r value already. When I check the formula for the test for significance for correlations, t only depends on N and r, and since df also depend on N, the p-value is fully determined by N and r. For given N and r, you always get the exact same p-value. Fluctuations don’t enter into it again, they’re part of r.
I was/am arguing, that the senior researcher meant:
1) We expected the same r (because that was our best guess based on prior data).
2) Given the very similar r and N, by the above formula p was expected to be similar.
I agree with you that the researcher probably underappreciated the degree of variation to be expected in r. (Not because of your example, but from general experience, including the limits of my own intuitions.)
I disagree that the quoted statement is evidence of your ‘wrong mental model’ because I just offered an alternative account of the statement (a competing theory) and your data seem insufficient to decide between the two. I’d also argue my account is the more parsimonious one, but we can easily agree to disagree on that.
Either way, this would only affect your motivating example, not your general point.
(Except the one where you say “[r =](0.3) in his sample of 110 (giving power of 85.5%), but due to fluctuation in the sampling, perceives a very large p-value (between 0.04 and 0.05*, where 2% of p-values land in this case).”. because for r = 0.3 and N = 110, t(108) = 3.27, p < 0.01.)
LikeLike
Ah, right, I think I get your point. If one would observe r=0.3 with n=110, p would be <0.01. And if one would observe the same r, the p would be the same. My bad! I updated the post a bit.
If you would observe an r with p between 0.04 and 0.05, would it really be justified to expect the same r and p again, when true r is unknown and you keep the same sample size? Perhaps, but the CI95 for observed r=0.3 and n=110 would be 0.12-0.461 – a huge variation, and there’s nothing that says one value is more probable than another. Still, it might be your best guess. But if you get a large p, the observed r may lead you astray.
I’m thinking, we don’t know that second r yet. We know the first p-value was 0.04 < p < 0.05. This is a rare occurrence when sampling from a population with r = 0.3, with n = 110. If the population r was 0.3 and you observed a p between 0.04 and 0.05, this means you observed r of ≈ 0.19, and you would expect to see that again. When I ran the simulations (in the end of the code file), this expectation was correct 1-4 times in 10k samples.
Given a) how rare an occurrence has happened here, b) that the scholar did not acknowledge the rarity in any way, and c) my understanding (stemming from the rest of his presentation) that he had minimal statistical training, I stand by my prior interpretation of what he meant. But I’m happy to change my opinion if I’m still not getting the point here.
LikeLike
I think we’re on the same page now.
I’m not sure your ‘1-4 times in 10k samples’ is relevant here, as by my understanding that is based on samples from a population with true r = 0.3. Obviously the expectation will rarely be met if the initial estimate of r = 0.19 is far from the true value.
But either way, the thing to do is of course to plan for the fact that your initial estimate was an overestimate (especially when it is a surprising find, i.e. would likely not have been found if the initial estimate was slightly lower) which the researcher clearly failed to do.
LikeLike
Thanky Thanky for all this good innmioatrof!
LikeLike
Very good even your article I will share in my social network
LikeLike
[…] The art of expecting p-values […]
LikeLike
GMiner 1.90 – Скачать SRBPolaris 3.5, NiceHash Miner Legacy
LikeLike